 Authors: Stephen Xie, Long (Tony) Lian
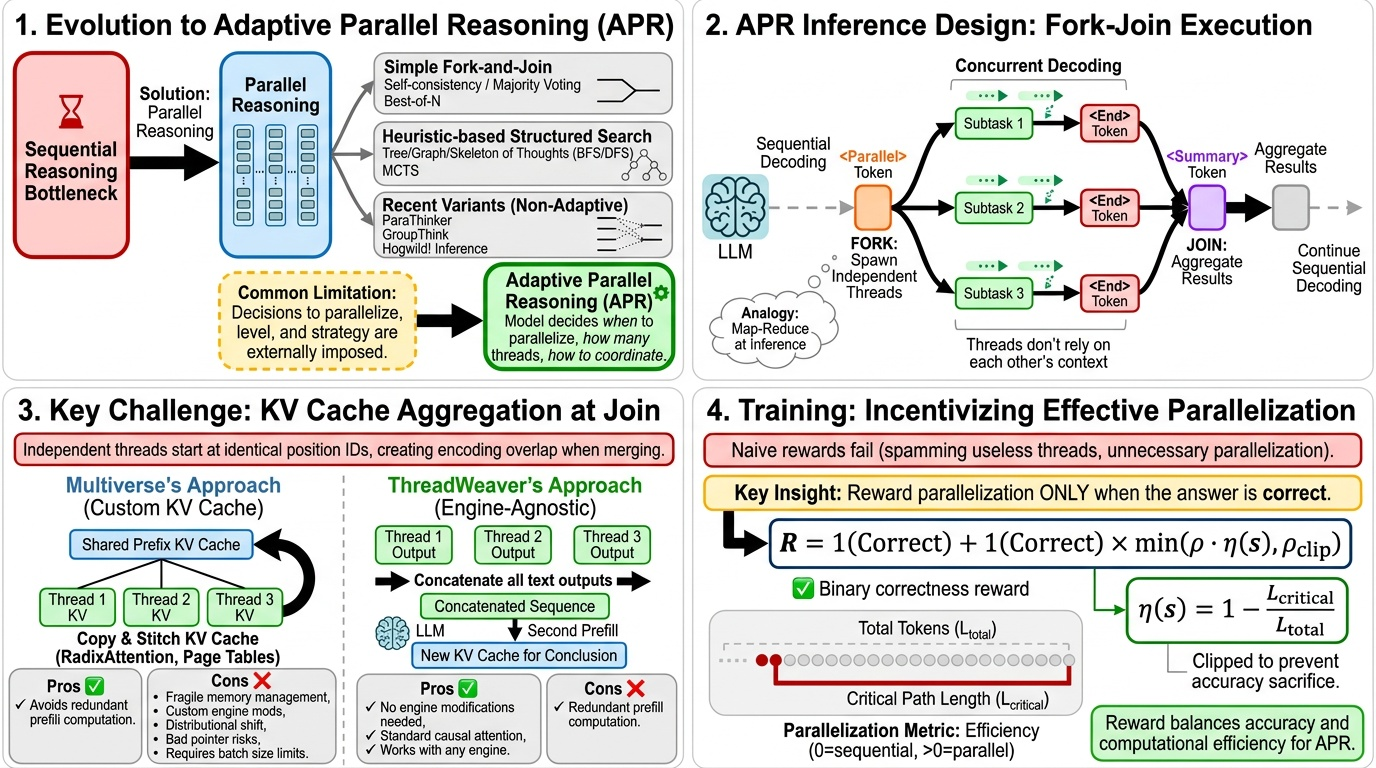
Authors: Stephen Xie, Long (Tony) Lian
TLDR:
What if a reasoning model could decide for itself when to decompose and parallelize independent subtasks, how many concurrent threads to spawn, and how to coordinate them based on the problem at hand? We provide a detailed analysis of recent progress in the field of parallel reasoning, especially Adaptive Parallel Reasoning.
Motivation
Recent progress in LLM reasoning capability has been largely driven by inference-time scaling, in addition to data and parameter scaling (OpenAI et al., 2024; DeepSeek-AI et al., 2025). Models that explicitly output reasoning tokens (through intermediate steps, backtracking, and exploration) now dominate math, coding, and agentic benchmarks. These behaviors allow models to explore alternative hypotheses, correct earlier mistakes, and synthesize conclusions rather than committing to a single solution (Wen et al., 2025).
What's wrong with sequential reasoning?
Scaling sequential reasoning tokens comes at a cost, as models risk exceeding effective context limits (Hsieh et al., 2024). The accumulation of intermediate exploration paths makes it challenging for the model to disambiguate amongst distractors when attending to information in its context, leading to a degradation of model performance, also known as context-rot (Hong, Troynikov and Huber, 2025).
Latency also grows proportionally with reasoning length. For complex tasks requiring tens of millions of tokens for exploration and planning, it's not uncommon to see users wait tens of minutes or even hours for an answer (Qu et al., 2025).
As we continue to scale along the output sequence length dimension, we also make inference slower, less reliable, and more compute intensive.
Parallel reasoning has emerged as a natural solution. Instead of exploring paths sequentially (Gandhi et al., 2024) and accumulating the context window at every step, we can allow models to explore multiple threads independently (threads don't rely on each other's context) and concurrently (threads can be executed at the same time).
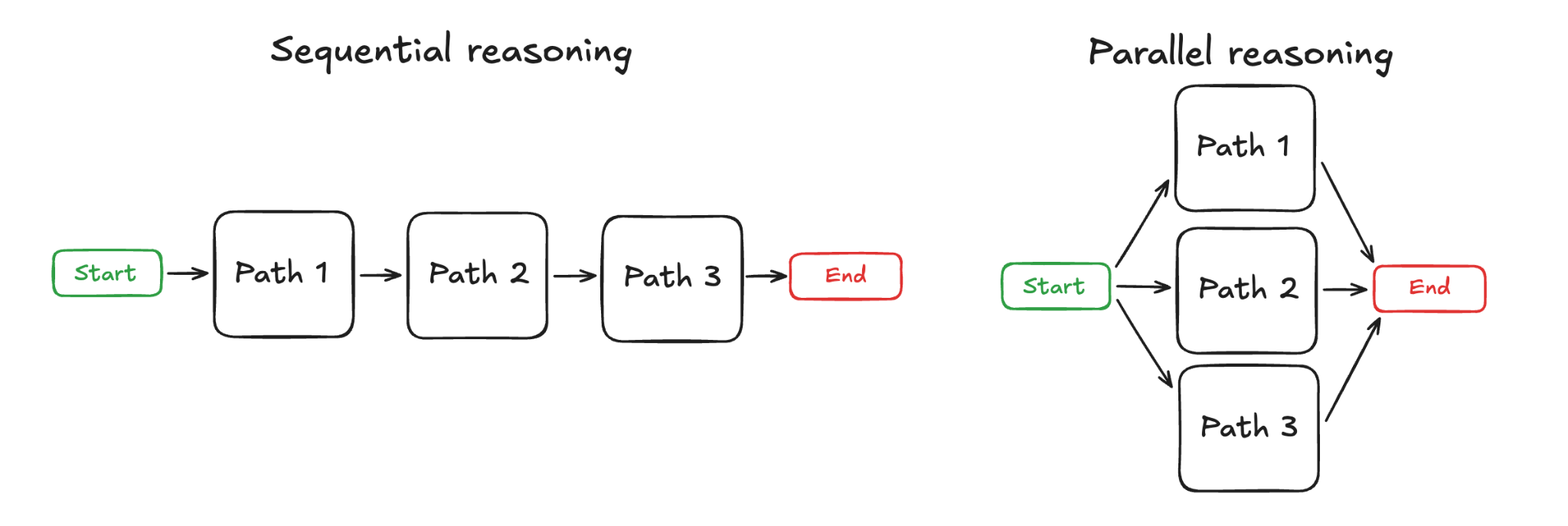
Figure 1: Sequential vs. Parallel Reasoning
Over recent years, a growing body of work has explored this idea across synthetic settings (e.g. Countdown (Katz, Kokel and Sreedharan, 2025)), real-world math problems, and general reasoning tasks.
Existing approaches to parallel reasoning - and why they're not enough
Simple fork-and-join
Self-consistency/Majority Voting - independently sample multiple complete reasoning traces, extract final answer from each, and return the most common one (Wang et al., 2023).
Best-of-N - similar to self-consistency, but uses a trained verifier to select the best solution instead of using majority voting (Stiennon et al., 2022).
Although simple to implement, these methods often contain redundant computation across branches since trajectories are sampled independently.
Heuristic-based Structured Search
Tree / Graph / Skeleton of Thoughts - a family of structured decomposition methods that explores multiple alternative "thoughts" using known search algorithms (BFS/DFS) and prunes via LLM-based evaluation (Yao et al., 2023; Besta et al., 2024; Ning et al., 2024).
Monte-Carlo Tree Search (MCTS) - estimate node values by sampling random rollouts and expanding the search tree with Upper Confidence Bound (UCB) style exploration-exploitation (Xie et al., 2024; Zhang et al., 2024).
These methods improve upon simple fork-and-join by decomposing tasks into non-overlapping subtasks; however, they require prior knowledge about the decomposition strategy, which is not always known.
Recent Variants
ParaThinker - train model to run in two fixed stages; first generate multiple reasoning threads in parallel, then synthesize them. They introduce trainable control tokens (<think_i>) and thought-specific positional embeddings to enforce independence during reasoning and controlled integration during summarization via a two-phase attention mask (Wen et al., 2025).
GroupThink - multiple parallel reasoning threads can see each other's partial progress at token level and adapt mid-generation. Unlike prior concurrent methods that operate on independent requests, GroupThink runs a single LLM producing multiple interdependent reasoning trajectories simultaneously (Hsu et al., 2025).
Hogwild! Inference - multiple parallel reasoning threads share KV cache and decide how to decompose tasks without an explicit coordination protocol. Workers generate concurrently into a shared attention cache using RoPE to stitch together individual KV blocks in different orders without recomputation (Rodionov et al., 2025).
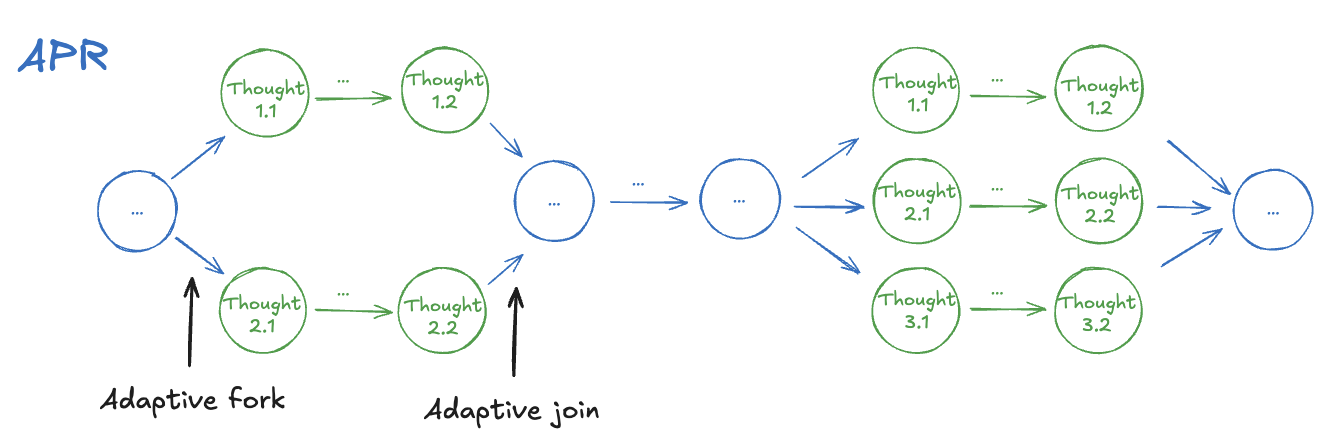
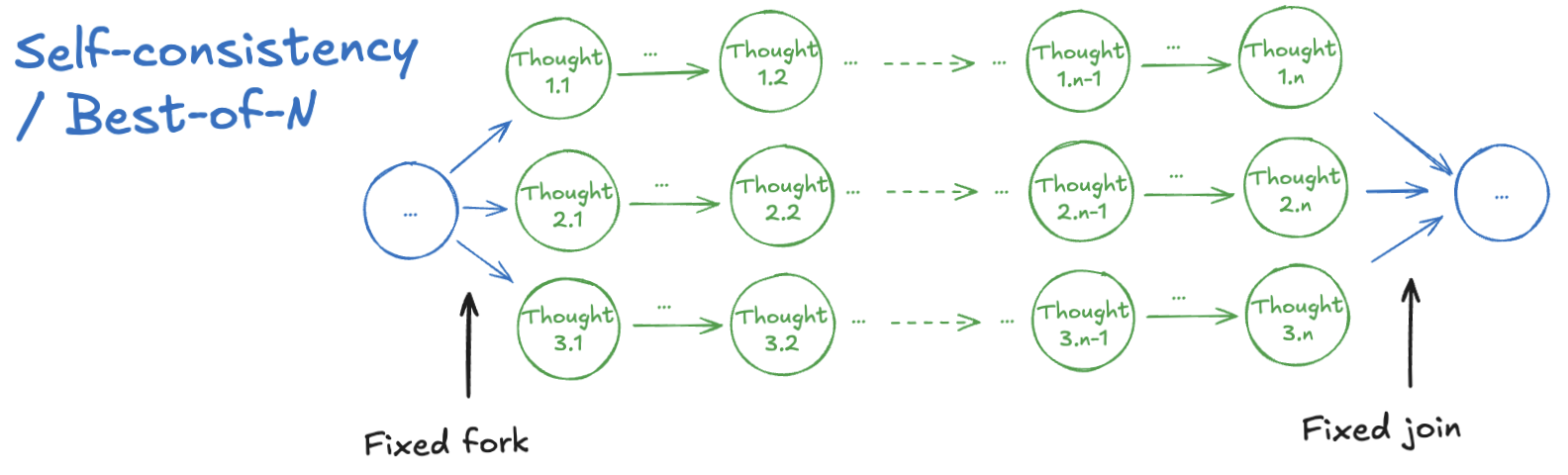
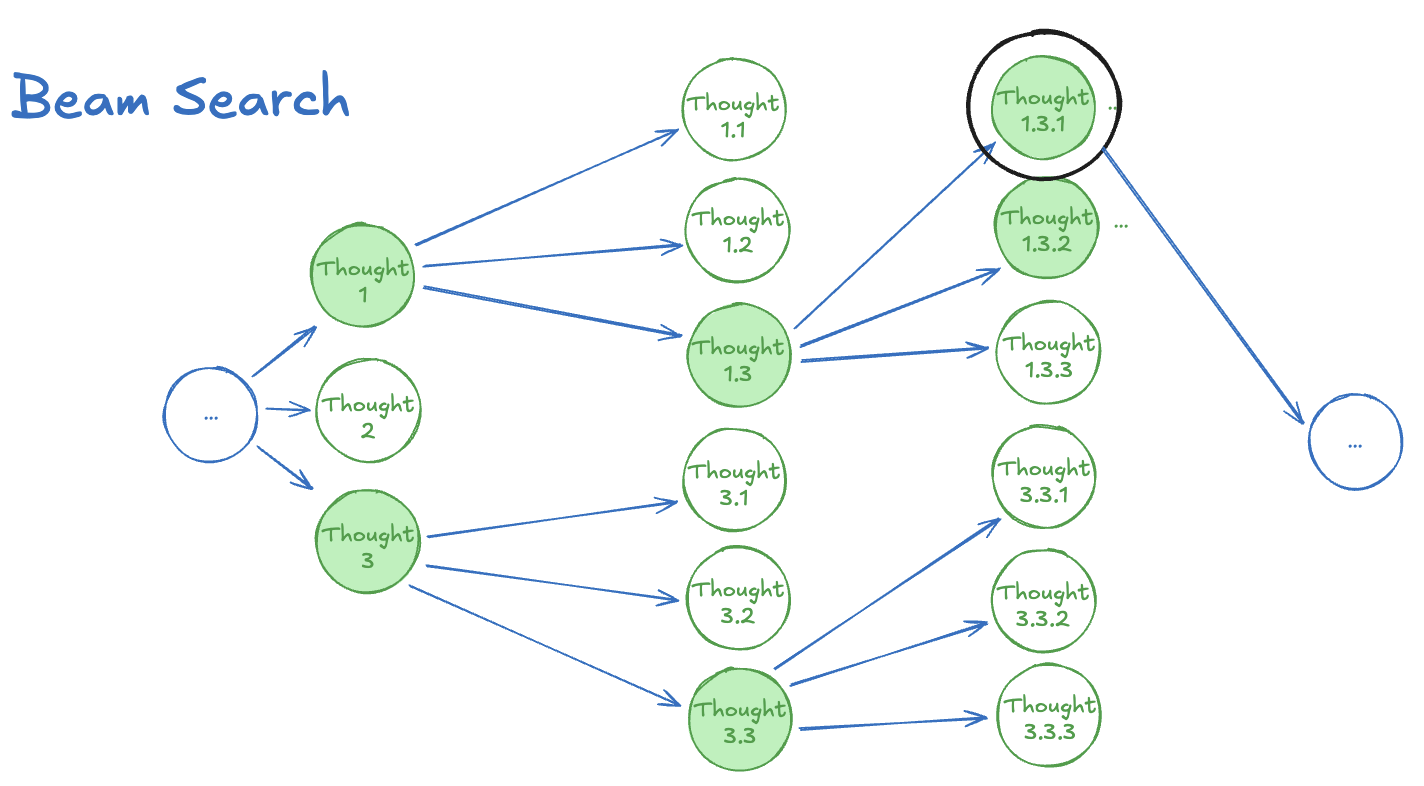
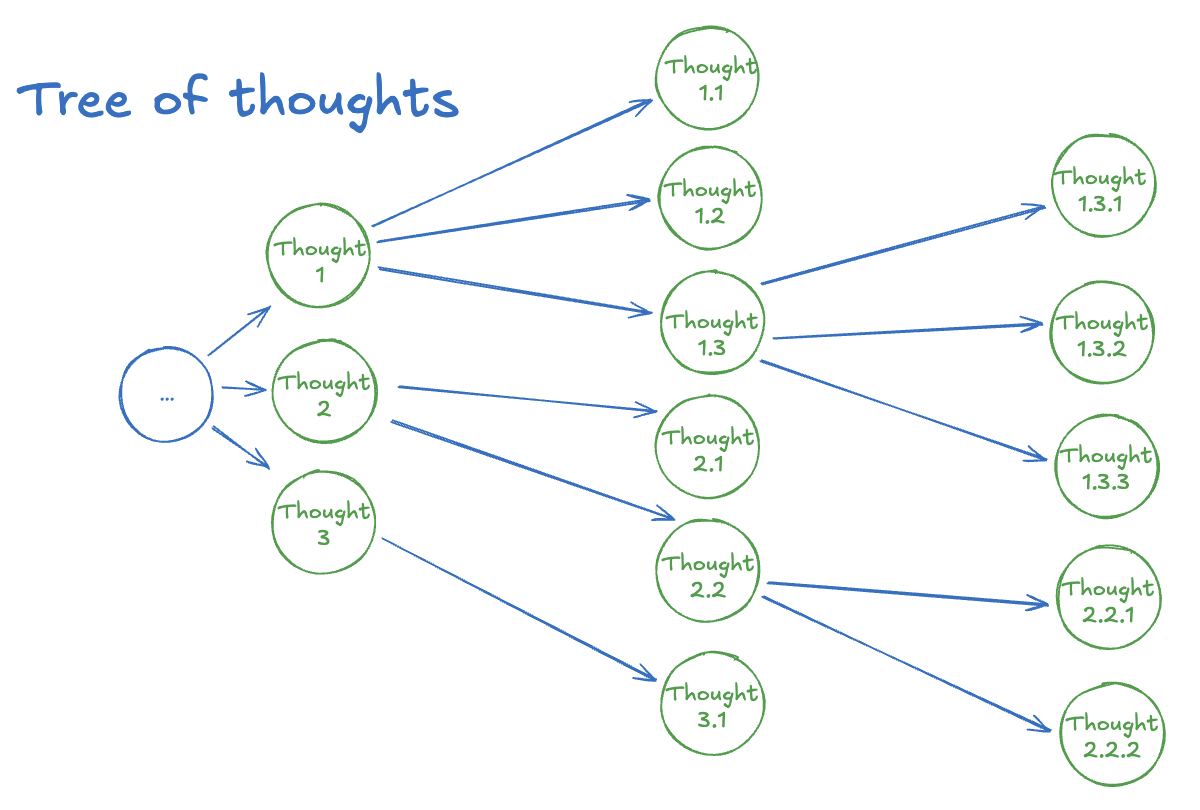
Figure 2: Various Strategies for Parallel Reasoning
The methods above share a common limitation: the decision to parallelize, the level of parallelization, and the search strategy are imposed on the model, regardless of whether the problem actually benefits from it.
However, different problems need different levels of parallelization, and that is something critical to the effectiveness of parallelization.
For example, a framework that applies the same parallel structure to "What's 25+42?" and "What's the smallest area you need to rotate a unit-length line by 180 degrees in a plane?" is wasting compute on the former and probably using the wrong decomposition strategy for the latter.
In these previous approaches that we just introduced, the model is not taught this adaptive behavior. A natural question arises:
What if the model could decide for itself when to parallelize, how many threads to spawn, and how to coordinate them based on the problem at hand?
Introducing Adaptivity to Parallel Reasoning
What does "adaptive" mean?
Formally defined, adaptivity refers to the model's ability to dynamically allocate compute between parallel and serial operations at inference time. In other words, a model with adaptive parallel reasoning (APR) capability is taught to coordinate its control flow – when to generate sequences sequentially vs. in parallel.
It's important to note that the concept of adaptive parallel reasoning is introduced by the work Learning Adaptive Parallel Reasoning with Language Models (Pan et al., 2025), but it is a paradigm instead of a specific method. In this work, we use APR to refer to the paradigm. We use the phrase "APR method" when we talk about the specific method. The APR method is an example of the APR (paradigm).
Why adaptive parallel reasoning?
Compared to ToT, APR doesn't need domain-specific heuristics for decomposition. During RL, the model learns general decomposition strategy from trial and error. In fact, models discover useful parallelization patterns, such as running the next step along with the self-verification of a previous step, or hedging a primary approach with a backup one, in an emergent manner that would be difficult to hand-design (Wu et al., 2025; Zheng et al., 2025).
Compared to BoN, APR avoids redundant computation. APR models have control over what each parallel thread will do before branching out. Therefore, APR can learn to produce a set of unique, non-overlapping subtasks before assigning them to independent threads (Pan et al., 2025; Yang et al., 2025).
Compared to non-adaptive approaches, APR can choose not to parallelize. Adaptive models can adjust the level of parallelization to match the complexity of the problem against the complexity and overhead of parallelization (Lian et al., 2025).
Implementation of adaptive parallel reasoning
Model outputs special tokens to adaptively control when to reason in parallel versus sequentially.
Prompt:
Evaluate $\sin(\arcsin 0.4 + \arcsin 0.5) \cdot \sin(\arcsin 0.5 - \arcsin 0.4)$.
Response:
<Parallel>
<Outlines>
<Outline>1: Algebraic approach using substitutions $$A = \arcsin(0.4)$$, $$B = \arcsin(0.5)$$ and the identity $$\sin(A+B)\sin(B-A) = \frac{\cos(2A) - \cos(2B)}{2}$$.
</Outline>
<Outline>2: Numerical approach by approximating substitution values and evaluating directly.
</Outline>
</Outlines>
<Path>1:
Substitute $A, B$. Use $\cos(2\theta) = 1 - 2\sin^2\theta$.$\cos(2A) = 1 - 2(0.4)^2 = 1 - 0.32 = 0.68$.$\cos(2B) = 1 - 2(0.5)^2 = 1 - 0.5 = 0.5$.Expression $= \frac{0.68 - 0.5}{2}$.
</Path>
<Path>2:
$A \approx 0.4115$ rad, $B \approx 0.5236$ rad.$\sin(A+B) \approx \sin(0.9351) \approx 0.8047$.$\sin(B-A) \approx \sin(0.1121) \approx 0.1118$.Product $\approx 0.8047 \times 0.1118 \approx 0.0899$.
</Path>
</Parallel>
Thread 1: $\frac{0.18}{2} = 0.09$
Thread 2: $\approx 0.09$ Both methods agree.
\boxed{0.09}
Figure 3: Example of an Adaptive Parallel Reasoning Trajectory from ThreadWeaver, manually condensed for ease of illustration.
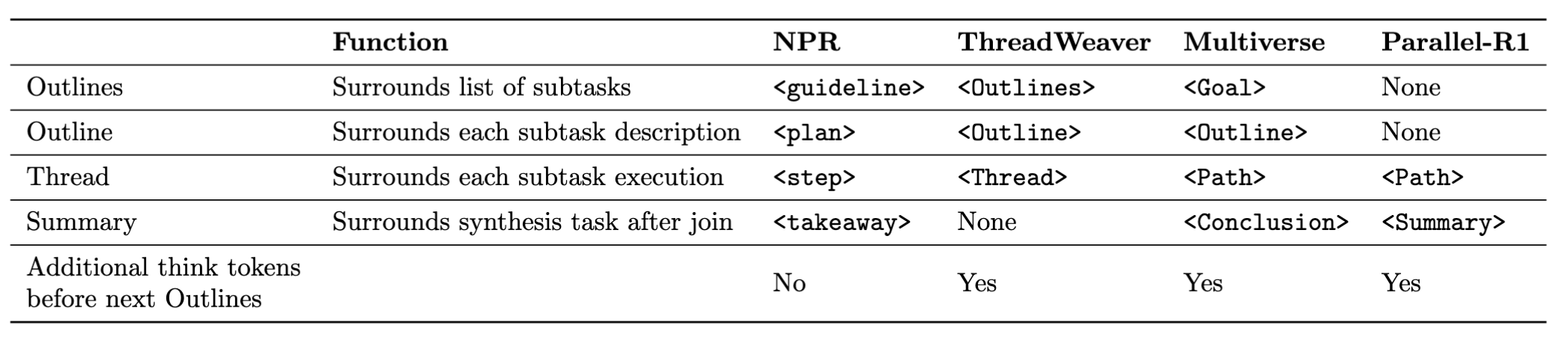
Figure 4: Special Tokens Variants across Adaptive Parallel Reasoning Papers
Inference and Training Co-Designs
How do we actually execute parallel branches? We take inspiration from computer systems, and specifically, multithreading and multiprocessing. A majority of the work can be considered as leveraging a fork-join design.
Fork-join design
At inference time, we are effectively asking the model to perform a map-reduce operation:
- Fork the problem into subtasks/threads, process them concurrently
- Join them into a final answer
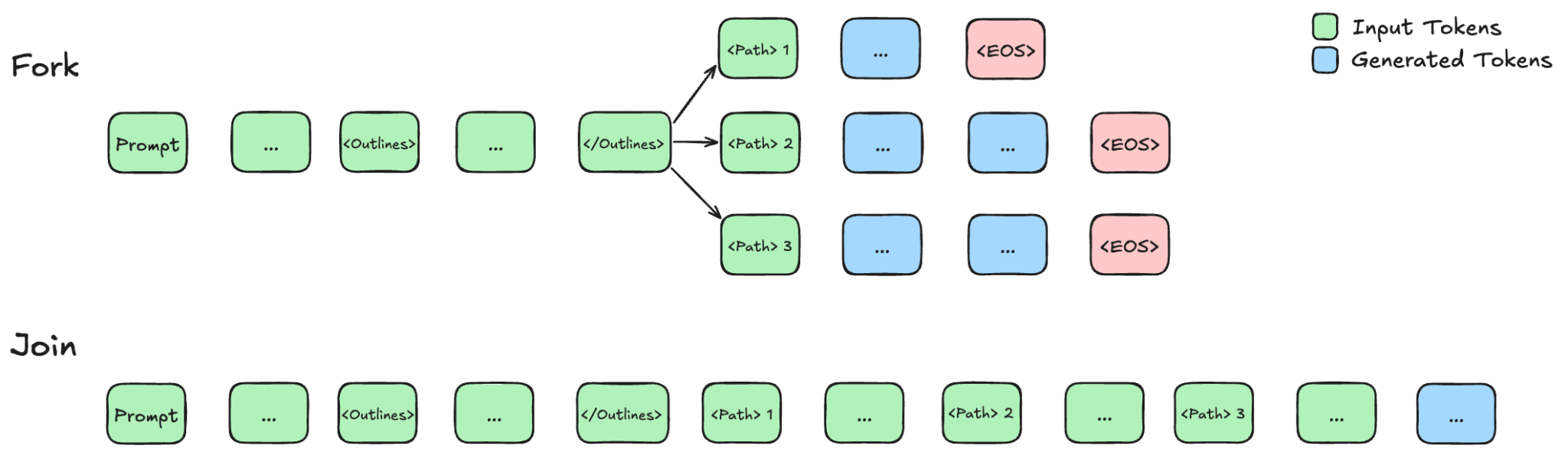
Figure 5: Fork-join Inference Design
Specifically, the model will encounter a list of subtasks. It will then prefill each of the subtasks and send them off as independent requests for the inference engine to process. These threads then decode concurrently until they hit an end token or exceed max length. This process blocks until all threads finish decoding and then aggregates the results. This is common across various adaptive parallel reasoning approaches. However, one issue arises during aggregation: the content generated in branches cannot be easily aggregated at the KV cache level. This is because tokens in independent threads start at identical position IDs, resulting in encoding overlap and non-standard behavior when merging KV cache back together. Similarly, since independent threads do not attend to each other, their concatenated KV cache results in a non-causal attention pattern, which the base model has not seen during training.
To address this issue, the field splits into two schools of thought on how to execute the aggregation process, defined by whether they modify the inference engine or work around it.
Multiverse's Approach: Custom KV Cache Handling
Before taking a deeper look into Multiverse's memory management, let's first understand how KV cache is handled up until the "join" phase. Notice how each of the independent threads share the prefix sequence, i.e., the list of subtasks. Without optimization, each thread needs to prefill and recompute the KV cache for the prefix sequence. However, this redundancy can be avoided with SGLang's RadixAttention, which organizes multiple requests into a radix tree, a trie (prefix tree) with sequence of elements with varying lengths instead of single elements. This way, the only new KV cache are those from independent thread generation.
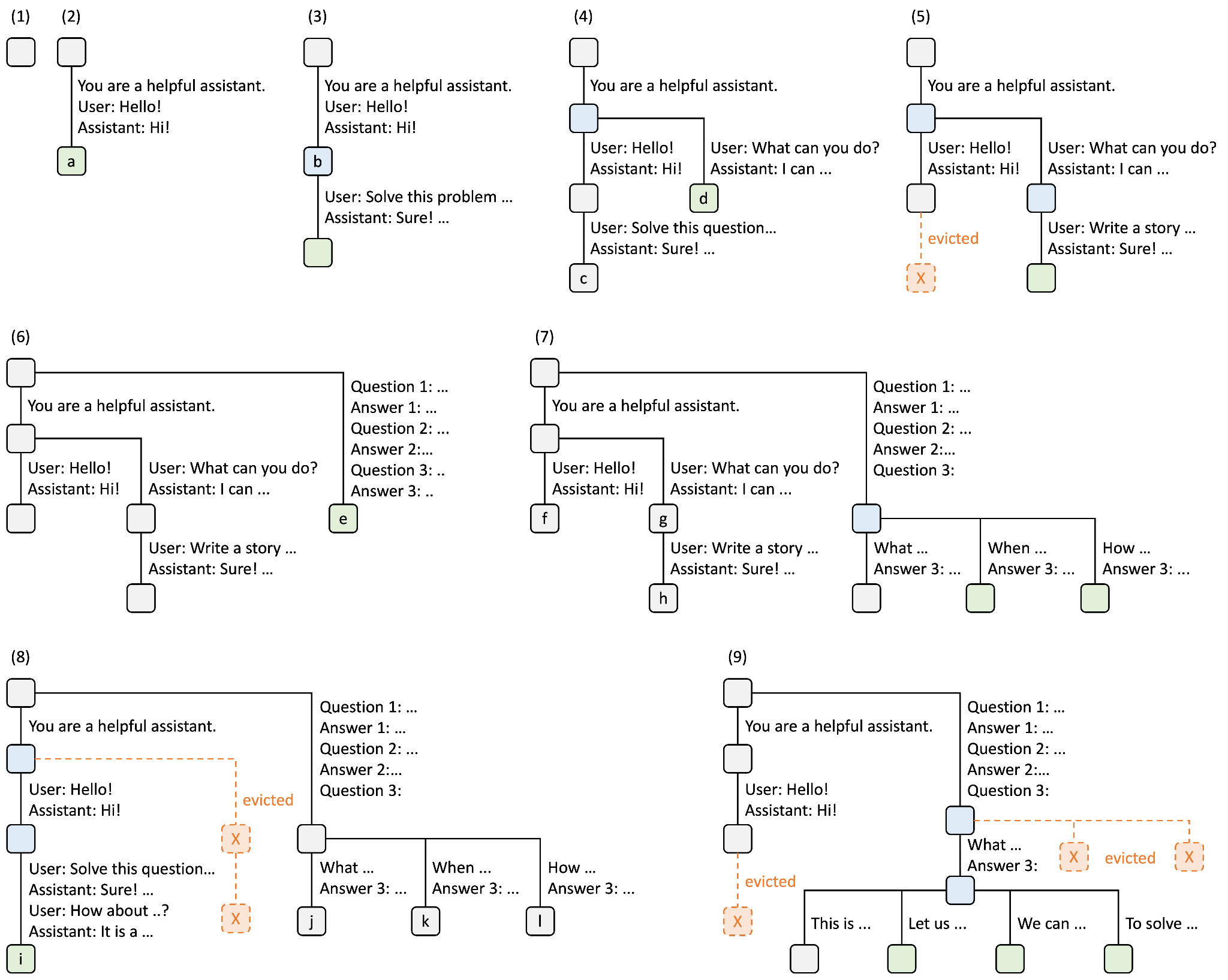
Figure 6: RadixAttention's KV Cache Management Strategy
Now, if everything went well, all the independent threads have come back from the inference engine. Our goal is now to figure out how to synthesize them back into a single sequence to continue decoding for next steps.
It turns out, we can reuse the KV cache of these independent threads during the synthesis stage. Specifically, Multiverse (as well as Parallel-R1, and NPR) modifies the inference engine to copy over the KV cache generated by each thread and edits the page table so that it stitches together non-contiguous memory blocks into a single KV cache sequence. This avoids the redundant computation of doing a second prefill and reuses existing KV cache as much as possible. However, this has several major limitations.
First, this approach requires modifying the inference engine to perform non-standard memory handling, which can result in unexpected behaviors. Specifically, since the synthesis request references KV cache from previous requests, it creates fragility in the system and the possibility of bad pointers. Another request can come in and evict the referenced KV cache before the synthesis request completes, requiring it to halt and trigger a re-prefilling of the previous thread request. This problem has led the Multiverse researchers to limit the batch size that the inference engine can handle, which restricts throughput.
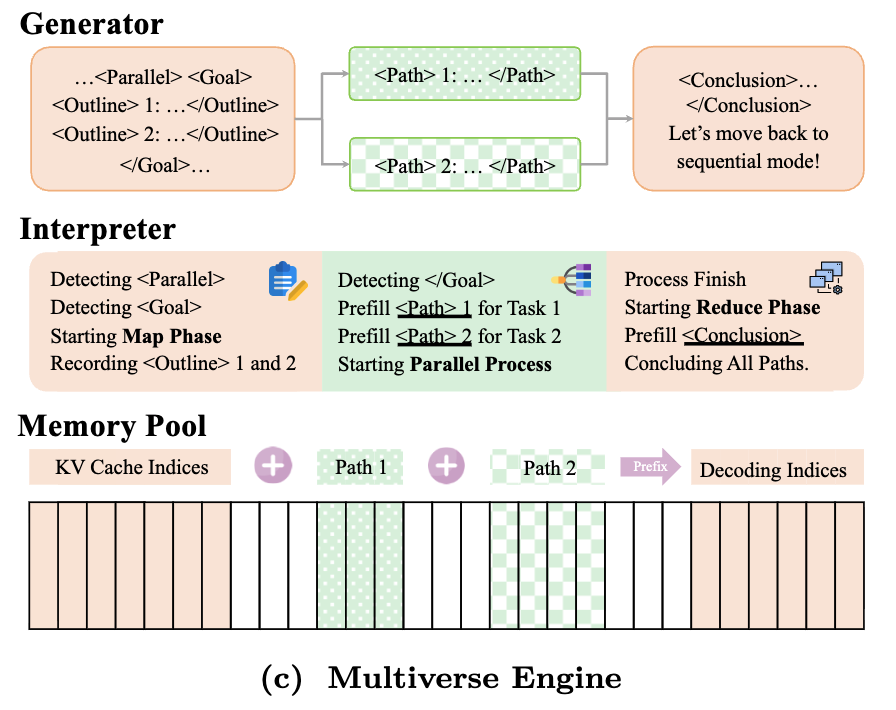
Figure 7: KV Cache "Stitching" During Multiverse Inference
Second, this approach modifies how models see the sequence, which creates a distributional shift that models are not pretrained on, therefore requiring more extensive training to align behavior. Specifically, when we stitch together KV cache this way, we create a sequence with non-standard position encoding. During independent threads generation, all threads started at the same position index and attended to the prior subtasks, NOT each other. So when the threads merge back, the resulting KV cache has a non-standard positional encoding and does not use causal attention. Therefore, this approach requires extensive training to align the model to this new behavior. To address this, Multiverse and other works apply a modified attention mask during training to prevent independent threads from attending to each other, aligning the training and inference behaviors.
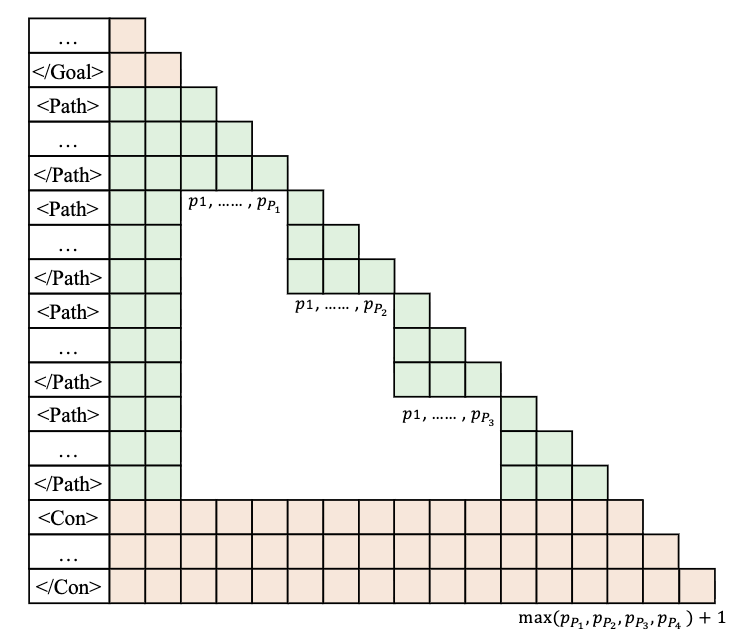
Figure 8: Multiverse's Attention Mask
With these issues arising from non-standard KV cache management, can we try an approach without engine modifications?
ThreadWeaver's Approach: Engine-agnostic
ThreadWeaver treats parallel inference purely as a client-side problem. The "Fork" process is nearly identical to Multiverse's, but the join phase handles memory very differently as it does NOT modify engine internals. Instead, the client concatenates all text outputs from independent branches into one contiguous sequence. Then, the engine performs a second prefill to generate the KV cache for the conclusion generation step. While this introduces computational redundancy that Multiverse tries to avoid, the cost of prefill is significantly lower than decoding. In addition, this does not require special attention handling during inference, as the second prefill uses causal attention (threads see each other), making it easier to adapt sequential autoregressive models for this task.
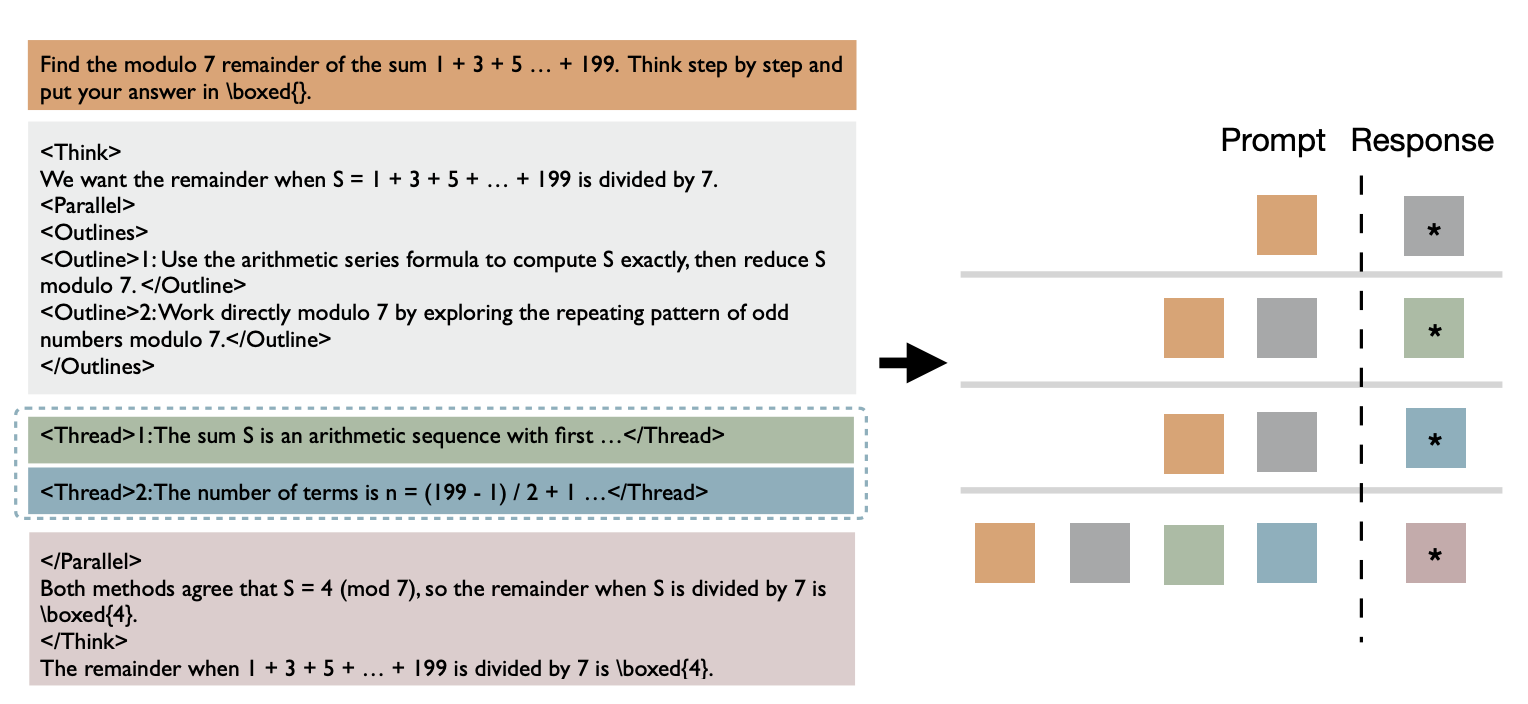
Figure 9: ThreadWeaver's Prefill and Decode Strategy
How should we train a model to learn this behavior? Naively, for each parallel trajectory, we can break it down into multiple sequential pieces following our inference pattern. For instance, we would train the model to output the subtasks given prompt, individual threads given prompt+subtask assignment, and conclusion given prompt+subtasks+corresponding threads. However, this seems redundant and not compute efficient. Can we do better?
Turns out, yes. As seen in ThreadWeaver, we can organize a parallel trajectory into a prefix-tree (trie), flatten it into a single sequence, and apply an ancestor-only attention mask during training (not inference!).
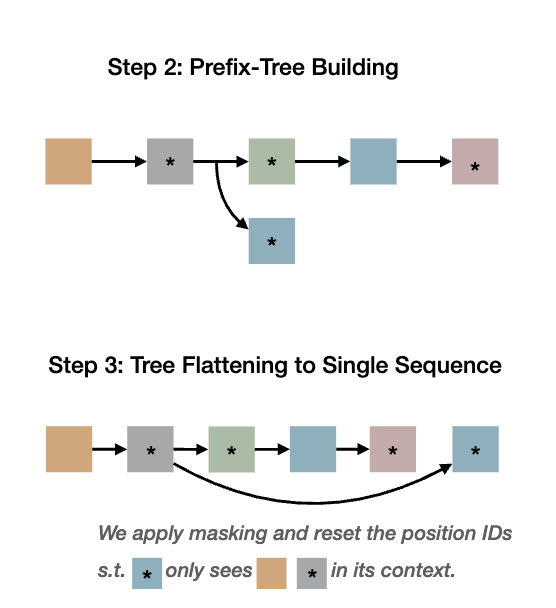
Figure 10: Building the Prefix-tree and Flattening into a single training sequence
Specifically, we apply masking and position IDs to mimic the inference behavior, such that each thread is only conditioned on the prompt+subtasks, without ever attending to sibling threads or the final conclusion.
Why does being engine-agnostic matter?
It makes adoption easy since you don't need to figure out a separate hosting method and can leverage existing hardware infra. It also gets better as existing inference engines get better. What's more, with an engine-agnostic method, we can serve a hybrid model that switches between sequential and parallel thinking mode easily.
Teaching with Demonstrations
Do we need demonstrations?
Yes, since you need to train to let the model output special tokens that orchestrate control flow. We found the instruction-following capabilities of base models insufficient for generating parallel threads.
An interesting question here is: does SFT training induce a fundamental reasoning capability for parallel execution that was previously absent, or does it merely align the model's existing pre-trained capabilities to a specific control-flow token syntax.
Typical wisdom is SFT teaches new knowledge; but contrary to common belief, some papers (Parallel R1, NPR) argue that their SFT demonstrations simply just induce format following (i.e., how to structure parallel requests). We leave it as future work for researchers.
Where do parallelization demonstrations come from?
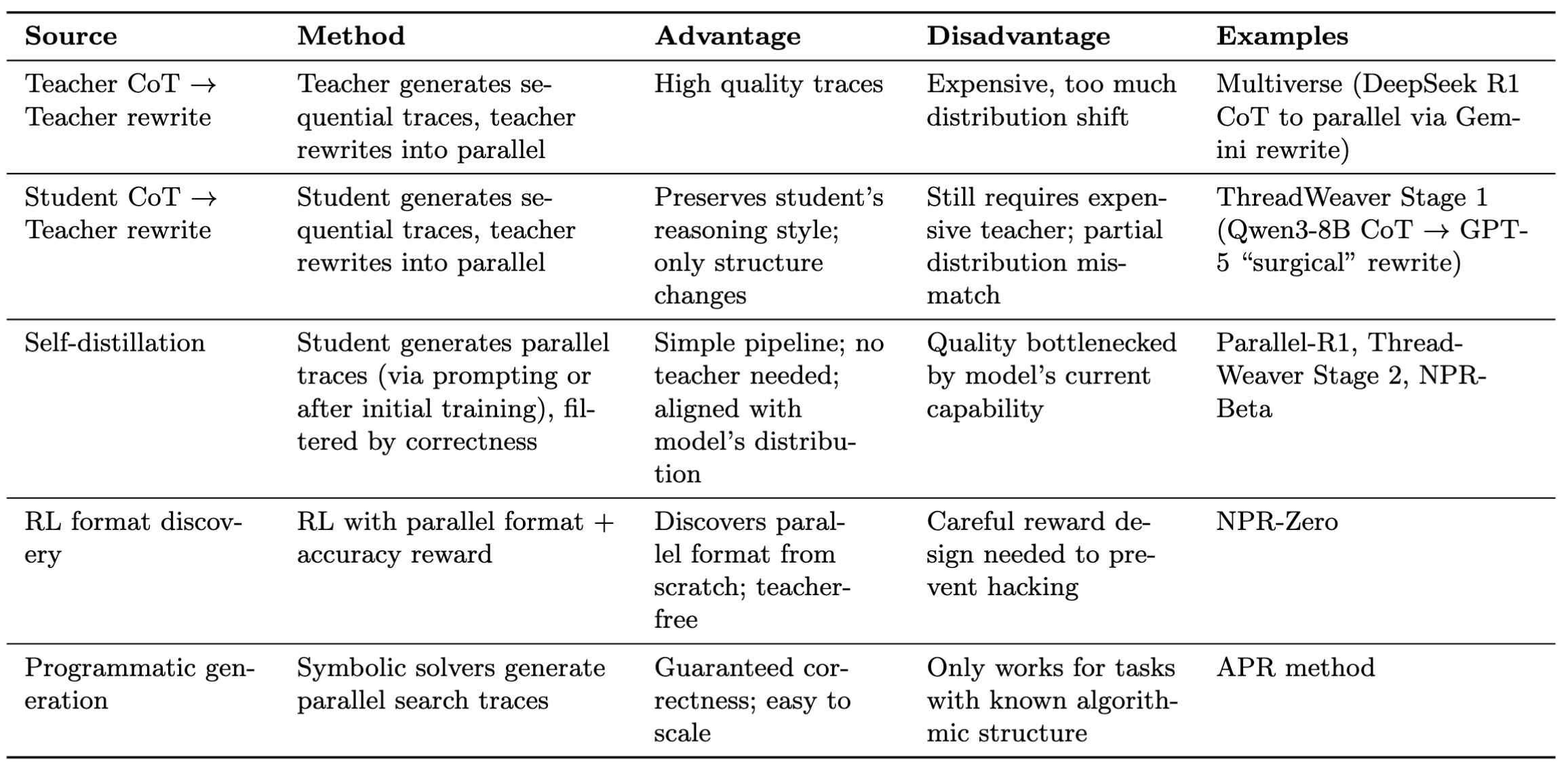
Figure 11: Sources of Parallelization Demonstration Data
Reward Design: How to incentivize parallelization?
In an ideal world, we only need to reward the outcome accuracy, and the parallelization pattern emerges naturally given it learns to output special tokens through SFT, similar to the emergence of long CoT. However, researchers (Zheng et al., 2025) observed that this is not enough, and we do in fact need parallelization incentives.
The question then becomes, how do we tell when the model is parallelizing effectively?
Rewarding Parallel Structures
Naively, we can give a reward for the number of threads spawned. But models can spawn many short, useless threads to hack the reward. Okay, that doesn't work. How about a binary reward for simply using parallel structure correctly? This partially solves the issue of models spamming new threads, but models still learn to spawn threads when they don't need to. The authors of Parallel-R1 introduced an alternating-schedule, only rewarding parallel structure 20% of the time, which successfully increased the use of parallel structure (13.6% -> 63%), but had little impact on overall accuracy.
With this structure-only approach, we might be drifting away from our original goal of increasing accuracy and reducing latency… How can we optimize for the Pareto frontier directly? Accuracy is simple – we just look at the outcome. How about latency?
Rewarding Parallel Efficiency
In sequential-only trajectories, we can measure latency based on the total number of tokens generated. To extend this to parallel trajectories, we can focus on the critical path, or the longest sequence of tokens that are causally dependent, as this directly determines our end-to-end generation time (aka wall-clock time). As an example, when there are two <Parallel> sections with five threads each, the critical path will go through the longest thread from the first parallel section, then any sequential tokens, then the longest thread from the second parallel section, and so on until the end of sequence.

Figure 12: Critical Path Length Illustration
The goal is to minimize the length of the critical path. Simultaneously, we would still like the model to be spending tokens exploring threads in parallel. To combine the two objectives, we can focus on making the critical path a smaller fraction of the total tokens spent. Authors of ThreadWeaver framed the parallelization reward as 1 - L_critical / L_total, which is 0 for sequential trajectory, and increases linearly as the critical path gets smaller compared to the total tokens generated.
How to combine this with accuracy reward?
Intuitively, when multiple trajectories are correct we should assign more reward to the trajectories that are more efficient at parallelization. But how about when they are all incorrect? Should we assign any reward at all? Probably not.
To formalize this:
R = Rcorrectness + Rparallel
Assuming we are dealing with binary outcome correctness, it can be formulated as:
R = 1(Correctness) + 1(Correctness) × (some parallelization metric)
This way, a model only gets a parallelization reward when it answers correctly, since we don't want to pose parallelization constraints on the model if it couldn't answer the questions right.

Figure 13: Differences in Reward Designs Across Adaptive Parallel Reasoning Works
Comparisons
When all is said and done, how well do these adaptive parallel methods actually perform?
Well…this is a hard question, as they differ in model choice and metrics.
Why do different APR papers use different models?
The model selection depends on the training method, SFT problem difficulty, and sequence length.
When running SFT on difficult datasets like s1k, which contains graduate-level math and science problems, researchers chose large base models (Qwen2.5 32B for Multiverse) to capture the complex reasoning structure behind the solution trajectories.
When running RL, researchers chose a small, non-CoT, instruct model (4B, 8B) due to compute cost constraints.
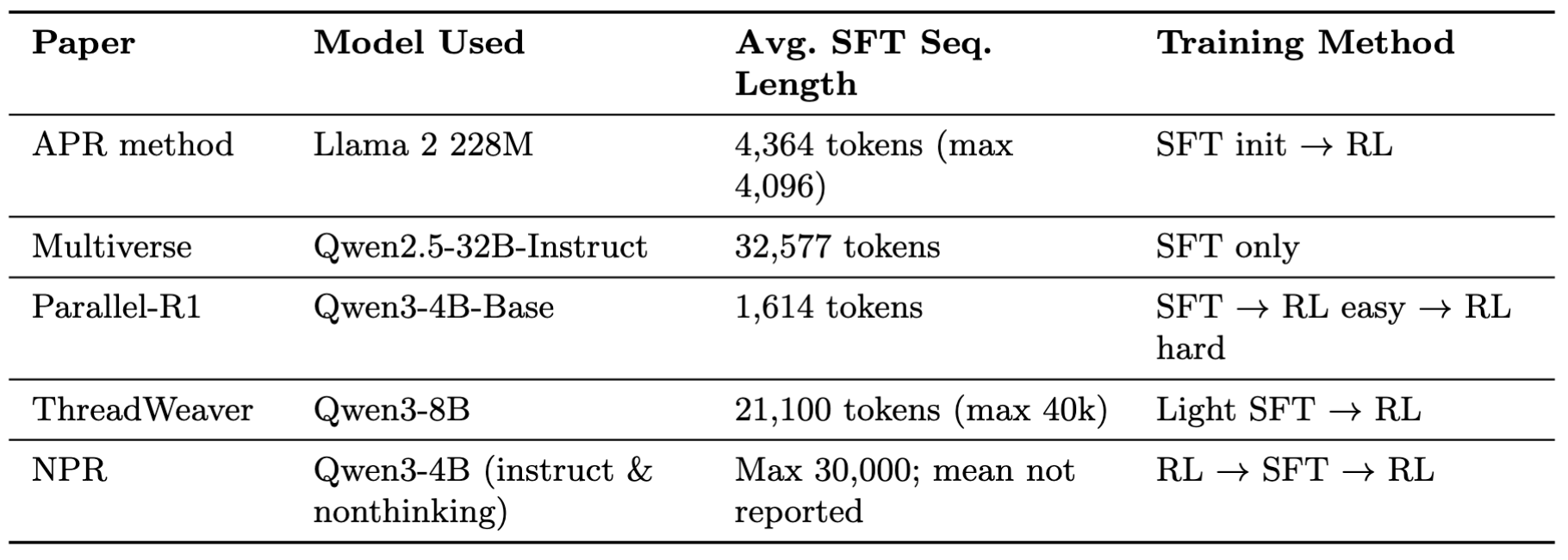
Figure 14: Difference in Model Choice Across Adaptive Parallel Reasoning Papers
Why do different APR papers use different metrics?
Each paper offers a slightly different interpretation about how adaptive parallel reasoning contributes to the research field. They optimize for different theoretical objectives, so they use slightly different sets of metrics.
Some papers (Multiverse, and ThreadWeaver) aim to deliver sequential AR model level accuracy at faster speeds. Multiverse shows that APR models can achieve higher accuracy under the same fixed context window. ThreadWeaver shows that the APR model achieves shorter end-to-end token latency (critical path length) while getting comparable accuracy.
NPR treats sequential fallback as a failure mode and optimizes for 100% Genuine Parallelism Rate, measured by percentage of parallel tokens versus total tokens.
Parallel-R1 did not focus on end-to-end latency and instead optimizes for exploration diversity and presents APR as a form of mid-training exploration scaffold that provides a performance boost after RL.
Discussions, Future Work, and Conclusion
While Adaptive Parallel Reasoning represents a promising step toward more efficient inference-time scaling, significant open questions remain.
- Does parallelization at inference-time consistently improve accuracy, or is it primarily valuable as a training-time exploration scaffold? Parallel-R1's results hint that the diversity induced by parallel structure during RL may matter more than the parallelization itself at test time.
- Can we design training methods that account for available compute budget at inference time, so parallelization decisions are hardware-aware rather than purely problem-driven?
- There's also a persistent tendency for models to collapse back to sequential reasoning when parallelization rewards are relaxed. Parallel-R1 authors showed that removing parallelization reward after 200 steps results in the model reverting to sequential behavior (Zheng et al., 2025). Is this a training stability issue, a reward signal design issue, or evidence that parallel structure genuinely conflicts with how autoregressive pretraining shapes the model's prior?
- What if we allow parallelization depth > 1? Recent work in recursive language models (RLMs) effectively manages long context and shows promising inference-time scaling capabilities (Zhang, Kraska and Khattab, 2026). How well do RLMs perform when trained with end-to-end RL that incentivizes adaptive parallelization?
Acknowledgements
We thank Nicholas Tomlin and Alane Suhr for providing us with helpful feedback. We thank Christopher Park, Karl Vilhelmsson, Nyx Iskandar, Georgia Zhou, Kaival Shah, and Jyoti Rani for their insightful suggestions. We thank Vijay Kethana, Jaewon Chang, Cameron Jordan, Syrielle Montariol, Erran Li, and Anya Ji for their valuable discussions. We thank Jiayi Pan, Xiuyu Li, and Alex Zhang for their constructive correspondences about Adaptive Parallel Reasoning and Recursive Language Models.
References
Besta, M. et al. (2024) "Graph of Thoughts: Solving Elaborate Problems with Large Language Models," Proceedings of the AAAI Conference on Artificial Intelligence, 38(16), pp. 17682–17690. https://doi.org/10.1609/aaai.v38i16.29720.
DeepSeek-AI et al. (2025) "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning," Nature, 645(8081), pp. 633–638. https://doi.org/10.1038/s41586-025-09422-z.
Gandhi, K. et al. (2024) "Stream of Search (SoS): Learning to Search in Language." arXiv. https://doi.org/10.48550/arXiv.2404.03683.
Hong, K., Troynikov, A. and Huber, J. (2025) Context Rot: How Increasing Input Tokens Impacts LLM Performance. Chroma. https://research.trychroma.com/context-rot.
Hsieh, C.-P. et al. (2024) "RULER: What's the Real Context Size of Your Long-Context Language Models?" arXiv. https://doi.org/10.48550/arXiv.2404.06654.
Hsu, C.-J. et al. (2025) "Group Think: Multiple Concurrent Reasoning Agents Collaborating at Token Level Granularity." arXiv. https://doi.org/10.48550/arXiv.2505.11107.
Katz, M., Kokel, H. and Sreedharan, S. (2025) "Seemingly Simple Planning Problems are Computationally Challenging: The Countdown Game." arXiv. https://doi.org/10.48550/arXiv.2508.02900.
Lian, L. et al. (2025) "ThreadWeaver: Adaptive Threading for Efficient Parallel Reasoning in Language Models." arXiv. https://doi.org/10.48550/arXiv.2512.07843.
Ning, X. et al. (2024) "Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation." arXiv. https://doi.org/10.48550/arXiv.2307.15337.
OpenAI et al. (2024) "OpenAI o1 System Card." arXiv. https://doi.org/10.48550/arXiv.2412.16720.
Pan, J. et al. (2025) "Learning Adaptive Parallel Reasoning with Language Models." arXiv. https://doi.org/10.48550/arXiv.2504.15466.
Qu, X. et al. (2025) "A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond." arXiv. https://doi.org/10.48550/arXiv.2503.21614.
Rodionov, G. et al. (2025) "Hogwild! Inference: Parallel LLM Generation via Concurrent Attention." arXiv. https://doi.org/10.48550/arXiv.2504.06261.
Stiennon, N. et al. (2022) "Learning to summarize from human feedback." arXiv. https://doi.org/10.48550/arXiv.2009.01325.
Wang, X. et al. (2023) "Self-Consistency Improves Chain of Thought Reasoning in Language Models." arXiv. https://doi.org/10.48550/arXiv.2203.11171.
Wen, H. et al. (2025) "ParaThinker: Native Parallel Thinking as a New Paradigm to Scale LLM Test-time Compute." arXiv. https://doi.org/10.48550/arXiv.2509.04475.
Wu, T. et al. (2025) "Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning." arXiv. https://doi.org/10.48550/arXiv.2512.07461.
Xie, Y. et al. (2024) "Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning." arXiv. https://doi.org/10.48550/arXiv.2405.00451.
Yang, X. et al. (2025) "Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation." arXiv. https://doi.org/10.48550/arXiv.2506.09991.
Yao, S. et al. (2023) "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." arXiv. https://doi.org/10.48550/arXiv.2305.10601.
Zhang, A.L., Kraska, T. and Khattab, O. (2026) "Recursive Language Models." arXiv. https://doi.org/10.48550/arXiv.2512.24601.
Zhang, D. et al. (2024) "Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B." arXiv. https://doi.org/10.48550/arXiv.2406.07394.
Zheng, T. et al. (2025) "Parallel-R1: Towards Parallel Thinking via Reinforcement Learning." arXiv. https://doi.org/10.48550/arXiv.2509.07980.